Introduction
It has now been about two weeks since the 2024 election, and, although some states like California and Alaska are still tabulating the final votes, we now have an all-but-final sense of where the national and state-level popular votes have landed. That also means that we can so how accurate, or rather how inaccurate, my predictive models were. Thus, I will begin by recapping my model and my predictions for the national popular vote, state-level results, and the electoral college, before then assessing the accuracy of my model, proposing hypotheses for my model’s inaccuracies, and then suggesting ways that I could have built my model better.
Recap of My Models and Predictions
For my predictions, I created three OLS models: one for the two-party national popular vote, one for the two-party state-level popular vote for states with public polling, and one for the two-party state-level popular vote for states without public polling.
National Popular Vote
My national popular vote model included variables for the October polling average, the September polling average, the (election year) Q2 national GDP growth, and a variable for incumbency. Below was what my model predicted for Harris’ two-party national vote share in the 2024 election:
| Harris Vote Share | Lower Bound | Upper Bound |
|---|---|---|
| 51.82711 | 46.55055 | 57.10367 |
As can be seen, my model predicted incorrectly a Harris national popular vote victory, with the lower bound of the 95% confidence interval being a Trump victory with 53.45% and the upper bound being a Harris landslide with a 57.1% share of the vote.
State-Level Vote and Electoral College
In terms of my state-level predictions, for the 23 states and two relevant congressional districts for which we had publicly available polling, I used an OLS model with variables for October and September polling averages, one- and two-cycle vote share lag, incumbent status, and the October national polling average. This model yielded the following predictions for these 25 states/districts:
| State | Harris Vote Share | Lower Bound | Upper Bound |
|---|---|---|---|
| Arizona | 50.17068 | 44.85019 | 55.49117 |
| California | 65.17024 | 59.78080 | 70.55968 |
| Florida | 48.36540 | 43.03339 | 53.69742 |
| Georgia | 50.42399 | 45.10149 | 55.74650 |
| Indiana | 41.34649 | 36.02409 | 46.66890 |
| Maine Cd 2 | 46.58067 | 41.26204 | 51.89930 |
| Maryland | 68.04048 | 62.66586 | 73.41510 |
| Massachusetts | 66.76200 | 61.39923 | 72.12476 |
| Michigan | 51.44157 | 46.11853 | 56.76461 |
| Minnesota | 53.89702 | 48.57408 | 59.21996 |
| Missouri | 43.16617 | 37.83319 | 48.49915 |
| Montana | 41.09607 | 35.77414 | 46.41800 |
| Nebraska | 40.09414 | 34.76453 | 45.42374 |
| Nebraska Cd 2 | 54.57686 | 49.24191 | 59.91181 |
| Nevada | 51.36874 | 46.04218 | 56.69530 |
| New Hampshire | 54.67997 | 49.34864 | 60.01130 |
| New Mexico | 54.62405 | 49.29581 | 59.95228 |
| New York | 59.86333 | 54.49855 | 65.22812 |
| North Carolina | 50.31757 | 44.98784 | 55.64730 |
| Ohio | 46.02362 | 40.70049 | 51.34675 |
| Pennsylvania | 51.23316 | 45.90608 | 56.56025 |
| Texas | 47.12235 | 41.80247 | 52.44224 |
| Virginia | 54.64381 | 49.32428 | 59.96335 |
| Washington | 60.57076 | 55.22182 | 65.91970 |
| Wisconsin | 51.20178 | 45.86424 | 56.53932 |
As can be seen, this model predicted a Harris victory in all seven key battleground states, with single-digit margin loses for her in Florida, Texas, Ohio, and Maine’s 2nd Congressional district. The upper bounds of this model had Harris also winning these four, while the lower bounds had Trump sweeping all seven key swing states in addition to Minnesota, Nebraska’s 2nd Congressional district, New Hampshire, New mexico, and Virginia.
For the remaining states for which there was no public polling, I used a similar OLS model that removed the state-level polling averages but added back in the September national polling average that the national OLS model used. Combining my state-level predictions from these two models
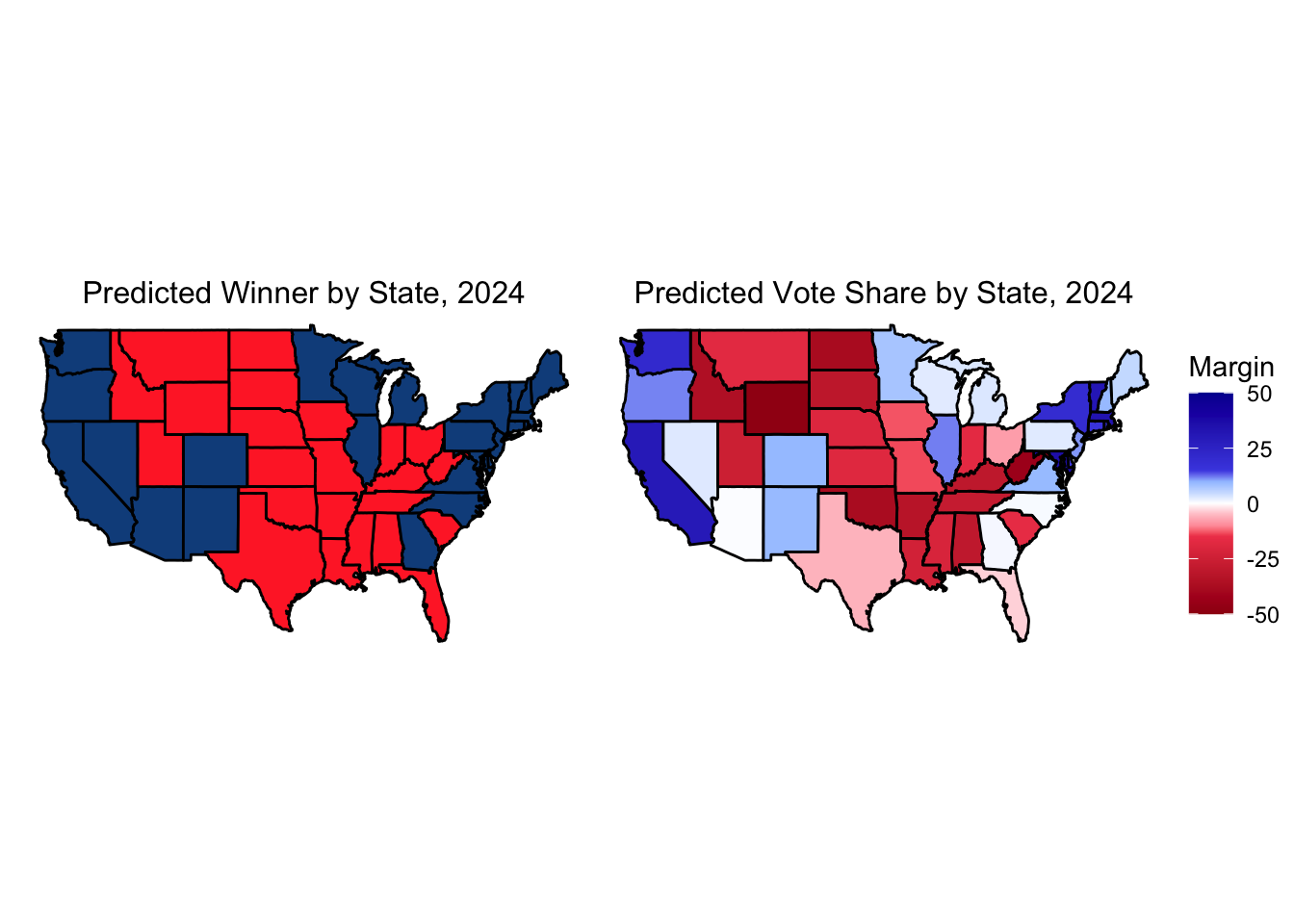
This would have yielded a 319-219 electoral college victory for Harris. Clearly, however, this did not quite happen.
Assessing My Accuracy
National Popular Vote
As of today, the New York Times has Harris at 73,846,289 votes nationwide and Trump at 76,488,195, meaning that Harris is (currently) taking about 49.12% of the two-party national popular vote. When looking at how this compares to my national model…
| Pred. Harris % | Real Harris % | Lower Bound | Upper Bound |
|---|---|---|---|
| 51.83 | 49.12 | 46.55 | 57.1 |
… we can see that, although my model did predict a 51.83% Harris victory that overestimate her share by 2.71%, this margin does squarely fall within my 95% confidence interval, being 2.57% above my lower bound for her vote share.
State-Level Vote and Electoral College
In terms of my state-level predictions, let’s first look at my OLS model for states/districts with public polling. Below is the table for these 23 states and two congressional districts, shaded by how much Harris in reality underperformed my model (as seen quantified in the “Error” column).
| State | Pred. Harris % | Real Harris % | Error | Lower Bound | Upper Bound |
|---|---|---|---|---|---|
| Arizona | 50.17068 | 47.15253 | -3.0181573 | 44.85019 | 55.49117 |
| California | 65.17024 | 60.72681 | -4.4434346 | 59.78080 | 70.55968 |
| Florida | 48.36540 | 43.37995 | -4.9854536 | 43.03339 | 53.69742 |
| Georgia | 50.42399 | 48.87845 | -1.5455431 | 45.10149 | 55.74650 |
| Indiana | 41.34649 | 40.34257 | -1.0039217 | 36.02409 | 46.66890 |
| Maine Cd 2 | 46.58067 | 45.37900 | -1.2016698 | 41.26204 | 51.89930 |
| Maryland | 68.04048 | 63.31036 | -4.7301230 | 62.66586 | 73.41510 |
| Massachusetts | 66.76200 | 62.66252 | -4.0994776 | 61.39923 | 72.12476 |
| Michigan | 51.44157 | 49.30156 | -2.1400148 | 46.11853 | 56.76461 |
| Minnesota | 53.89702 | 52.16725 | -1.7297758 | 48.57408 | 59.21996 |
| Missouri | 43.16617 | 40.64426 | -2.5219108 | 37.83319 | 48.49915 |
| Montana | 41.09607 | 39.63712 | -1.4589518 | 35.77414 | 46.41800 |
| Nebraska | 40.09414 | 39.38059 | -0.7135438 | 34.76453 | 45.42374 |
| Nebraska Cd 2 | 54.57686 | 52.12900 | -2.4478593 | 49.24191 | 59.91181 |
| Nevada | 51.36874 | 48.37829 | -2.9904538 | 46.04218 | 56.69530 |
| New Hampshire | 54.67997 | 51.40987 | -3.2701012 | 49.34864 | 60.01130 |
| New Mexico | 54.62405 | 53.00043 | -1.6236184 | 49.29581 | 59.95228 |
| New York | 59.86333 | 55.82881 | -4.0345193 | 54.49855 | 65.22812 |
| North Carolina | 50.31757 | 48.29889 | -2.0186761 | 44.98784 | 55.64730 |
| Ohio | 46.02362 | 44.27299 | -1.7506345 | 40.70049 | 51.34675 |
| Pennsylvania | 51.23316 | 48.98235 | -2.2508164 | 45.90608 | 56.56025 |
| Texas | 47.12235 | 42.98466 | -4.1376950 | 41.80247 | 52.44224 |
| Virginia | 54.64381 | 52.85012 | -1.7936960 | 49.32428 | 59.96335 |
| Washington | 60.57076 | 59.85109 | -0.7196666 | 55.22182 | 65.91970 |
| Wisconsin | 51.20178 | 49.53156 | -1.6702249 | 45.86424 | 56.53932 |
In all of the above states/districts, Harris did worse than my model predicted, with larger, more diverse states such as Florida, California, Texas, and New York having the biggest misses. This said, even my most inaccurate predictions still fell within the 95% confidence interval, although some, California, Florida, and Maryland in particular, were very close, coming within a point of falling below the lower bound.
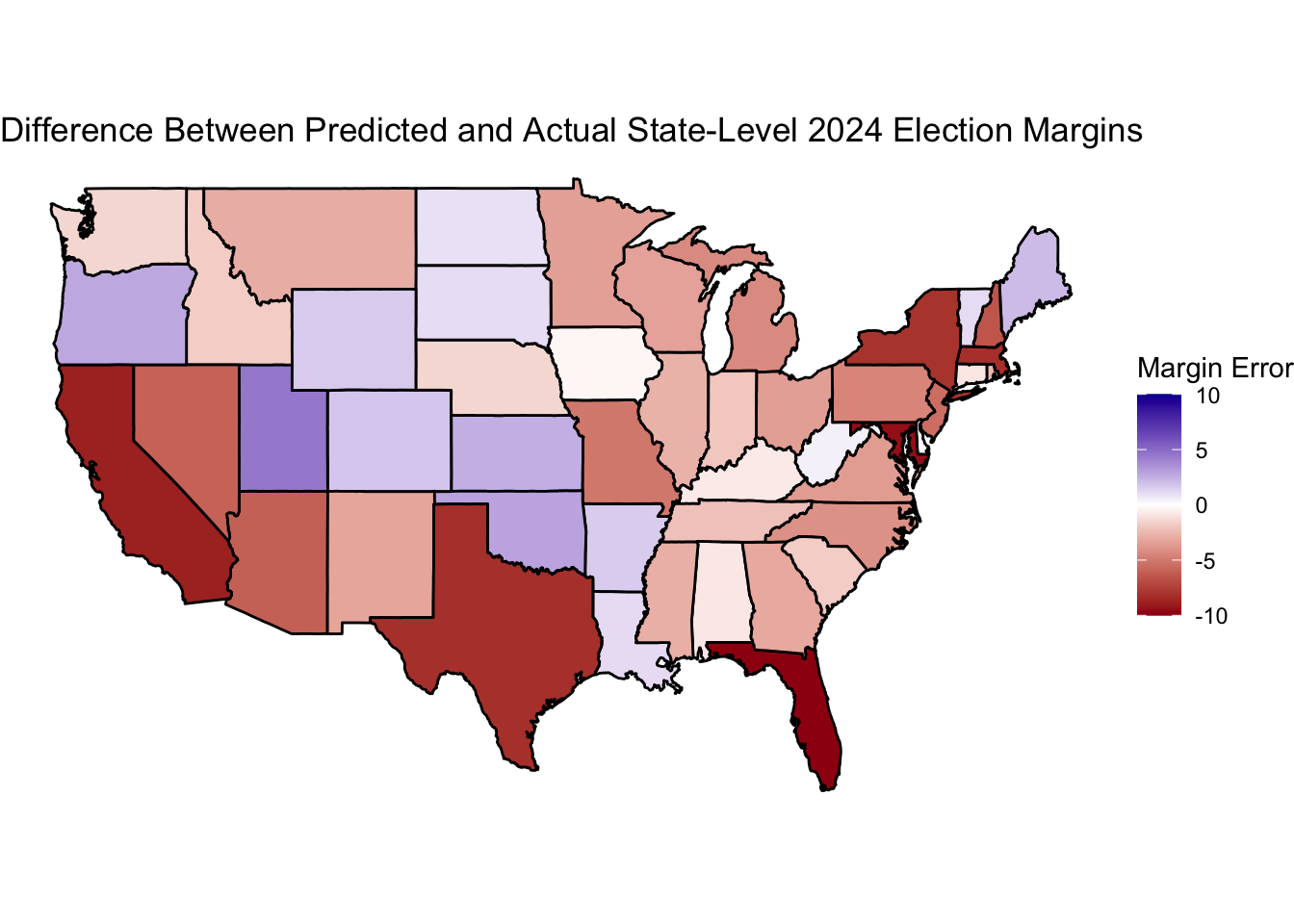
My second state-level model fared slightly better. Below is a map of how my combined predictions fared against reality, with blue-shaded states representing those which Harris did better than what my model(s) predicted and red-shared states being those which she did worse than my predictions.
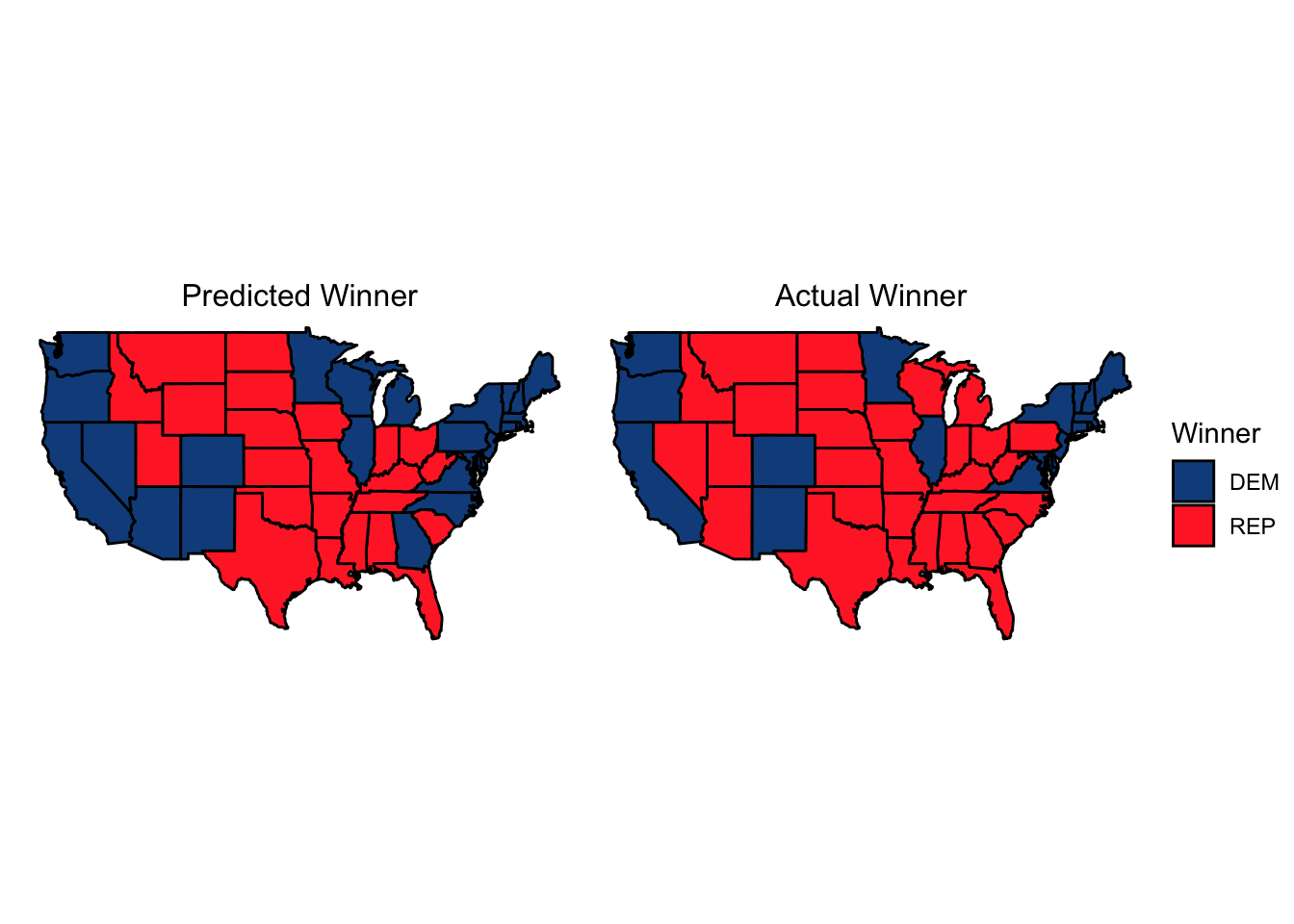
In terms of how this translates to who actually won each state, below are the maps of the predicted and actual state-level victors (with Alaska, Hawaii, DC, and the congressional districts in Nebraska and Maine not shown, but not changing between my model compared to the results):
In terms of quantifying how much my predictions were off, below are the bias, root mean squared error, and mean average error of my combined predictions:
| Bias | RMSE | MAE |
|---|---|---|
| -1.1 | 2.09 | 1.66 |
Although less than ideal, these values are not horribly far off the final results, especially given that this race ended up being less close than 2020 (although a 1-2% error still would have substantially swung the election). This said, there were differences in how accurate my two state-level models were.
In terms of my model for states with polling, this model fared notably worse, with higher bias, RMSE, and MAE values compared to my overall state-level predictions:
| Bias | RMSE | MAE |
|---|---|---|
| -2.49 | 2.79 | 2.49 |
Meanwhile, the subset of states for which I used the secondary model had almost no bias, and had notably lower RMSE and MAE values:
| Bias | RMSE | MAE |
|---|---|---|
| 0.02 | 1.24 | 1 |
I will explore potential reasons for this discrepancy below, but I preliminarily believe that the main reason behind this is that some of the largest shocking electoral shifts of the night happened in large, diverse states like California, New York, Texas, and Florida, all of which are important enough (either electorally or otherwise) for there to be public polling available for, whereas smaller, less diverse, electorally-safe states such as those in the Great Plains and Upper New England did not have polling.
Potential Explanations for Inaccuracies
Hypothesis 1: Incumbency
To begin with, I likely did not adequately consider how closely Harris would be tied to Biden in the eyes of the electorate. With the vast majority of Americans believing the country is headed in the “wrong direction” and with President Biden’s approval rating being stubbornly abysmal for so long, I should have better taken into account how poorly the electorate may view the current administration, particularly as Harris repeatedly either failed or refused to distance herself from her former running mate. In fact, at one point a few weeks ago, I strongly considered adding into my model a variable for the incumbent president’s (election year) June approval rating, but I decided against it because of prior beliefs that President Biden’s low approval rating was driven by concerns about age that would not play into a 2024 election with Harris as the Democratic nominee and by Democrats who would vote blue come November regardless. Clearly, this was not the case, and I should not have so quickly dismissed this variable and the notable rightwards shift its inclusion would have caused in my model. This is just one way I could have adjusted my incumbency variable though, and I am sure there could have been ways to make this more nuanced, especially given how complex the “incumbency” question was this year.
Hypothesis 2: Economics
Americans clearly are still feeling (or at least think they are feeling) the effects of inflation, and exit polls show that the economy was a top issue and that voters who cited the economy as their top issue swung towards Trump. This indicates that GDP was not an accurate indicator of how Americans were viewing the state of the economy. While this may have been a useful factor, it clearly did not capture the whole picture of how Americans have been viewing the economy. For example, I have seen numerous reports that exit polls show voters in swing states saying decisively that their local economy is doing better than four years ago, but that they perceive the national economy as doing worse, leading some to deem the current economic outlook in the country a “vibecession,” driven by perceptions and not necessarily reality. Because of these above reasons, I could have added in variables for inflation, RDI growth, or consumer sentiment. At one point I toyed with adding in a variable for RDI growth, but I ended up not using it because historically GDP growth had been a more accurate indicator. However, I did not let that stop me from including less historically-accurate variables such as September polling averages in my model since historical accuracy does not necessarily mean that such variables do not add nuance to my model in important ways.
Hypothesis 3: Demographics
While much more relevant to my state-level model, demographic-related electoral trends clearly played a crucial role in this election with minority voters, especially Hispanic, Asian, and Native American voters, swinging strongly towards the GOP. This has been a common explanation in the media for why states like New York, New Jersey, Illinois, California, Texas, and Florida all swung hard to the right. These demographic trends were somewhat caught preemptively by polling crosstabs, and to correct for this I could have added variables into my state-level models adjusting my polling models by trends with different demographic groups.
How I Might Have Changed My Model
While I have proposed a number of potential changes to my model above, I would have prioritized adding in variables for RDI growth and consumer sentiment to adjust how my model defined economic perceptions, I would have prioritized adding in some demographic-related weighting mechanism for my state-level models, and I would have added back in that aforementioned June approval rating variable that I almost included in prior blog posts. While my model still likely would have missed in some ways, with the benefit of hindsight I can see why models overestimated Harris and voters’ perceptions of the economy, and why my state-level model failed to adequately predict differing trends in some states and regions compared to others.
Altogether, I am fairly proud of how my model held up. While I did incorrectly predict the final result, with one or two minor adjustments the narrow victory for Harris that I predicted in the swing states easily could have shifted to being a narrow victory for Trump instead. I am also very pleased with how surprisingly well my supplementary state-level model held up, albeit with the aforementioned caveat, and I do feel that through these models and predictions I have learned more about America’s electorate and what truly seems to matter in elections here.